Welcome back to me and to you, it seems I’ve had quite a haitus but I’m back with a new tale of software development and the struggles that accompany that journey. So, kick back, take a load off, and join me in an exploration of Kubernetes, the Cluster Autoscaler, Cluster API, and the path to scaling from zero support.
Background
As part of $DAY_JOB I help to maintain the Kubernetes Cluster Autoscaler,
I also work on the Cluster API
provider implementation for the autoscaler as well as some other Cluster API
related components.
Way back in March of 2020, the Cluster API community began talking about an feature that would eventually become the Opt-in Autoscaling from Zero enhancement. This took us several months to discuss all the nuances and eventually it was merged. Since then, I have been working to realize this enhancement in the Cluster Autoscaler, and as of this week we have finaly merged this in PR 4840.
This was quite a long journey and it took many hands to get everything working as we expected. Much of this process was consumed with discussing various implementation options with the community and then learning how we could integrate those changes smoothly into the autoscaler.
At this point you might be asking “but elmiko, this article is supposed to be about client-go informers, what gives?” All good things in time, let me first explain a little about how scaling from zero works in the Cluster Autoscaler, and also how Cluster API works and why we needed dynamic Informers to be created during runtime.
Cluster Autoscaler and Scaling From Zero
Let’s talk a little about the Cluster Autoscaler and why scaling from zero can be a tricky thing to implement. Normally, in non zero replica situations, when the autoscaler will scale up it looks at the nodes in the node group (an autoscaler specific concept to identify groups of instances that can scale) and predicts the sizing of new nodes based on the nodes that are present. To perform that prediction it must use the current nodes to make its predictions.
But, when there are no nodes in the node group, and the autoscaler provider implementation has signaled that it supports scaling from zero replicas, then the autoscaler will use a node template to make its predictions. Each provider is responsible for implementing the node template interface functions and as such each provider will have a different methodology for determining this information.
So how does Cluster API do this?
Cluster API and Machine Templates
Cluster API has a relatively unique implementation when it comes to the autoscaler. Because it uses Kubernetes objects as an abstraction layer between the user and the infrastructure platform, it has a highly developed notion of shared information and slightly object oriented approach to how its information is contained in the API server.
The following graph shows the relationship between various Cluster API custom resources:
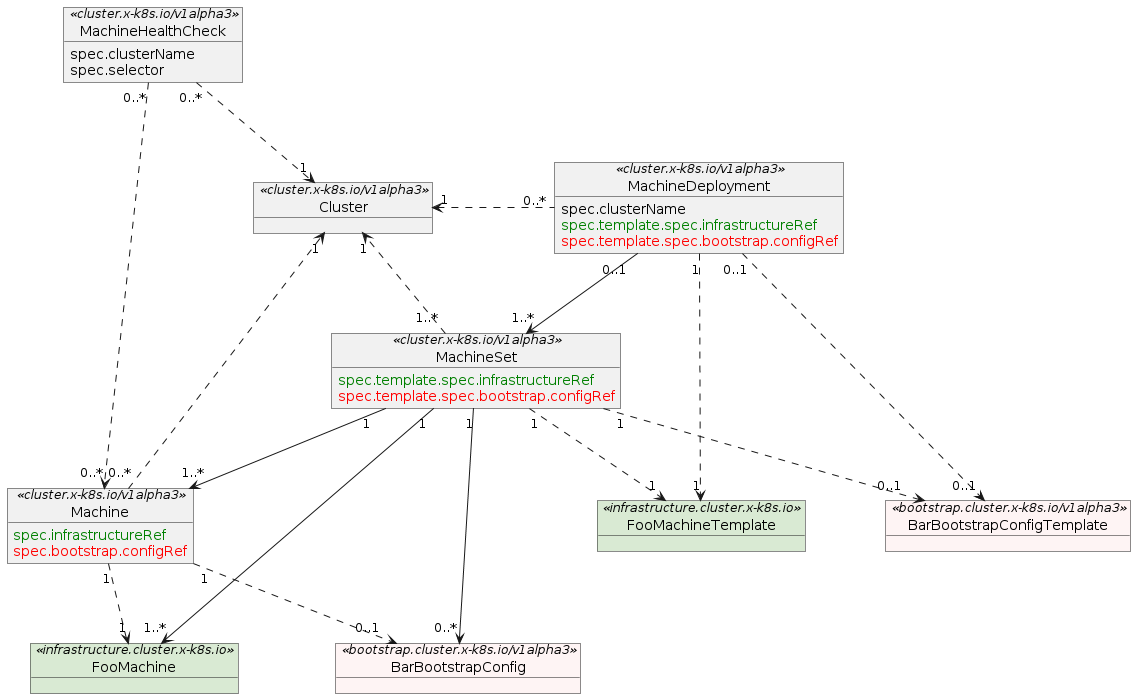
sourced from the Cluster API book
This arrangement of resources in Kubernetes allows the Cluster API controllers
to have abstract notions of how a Machine is defined by using the
infrastructure.cluster.x-k8s.io types. You will see the FooMachineTemplate
as a relation to the MachineSet and MachineDeployment types. This reference
is used when creating new Machines by the infrastructure provider controllers,
and allows several MachineSet/Deployments to use the same Machine templates.
What does all this mean for the Cluster Autoscaler then?
Cluster API and the Cluster Autoscaler
One of the things I find most convenient about working on Cluster API and the
autoscaler implementation is that MachineSets and MachineDeployments are direct
equivalents to the node group concept that the autoscaler uses internally.
This makes it very easy to recon about how the autoscaler interacts with node
groups, whether that is to inspect labels or taints on the nodes of that group,
or to calculate the size of the node group (essentially the replicas field).
This means that we must use a Kubernetes client inside of the Cluster API provider implementation to make sure that we can get the resource objects associated with the instances and nodes of the cluster. In fact, because Cluster API is commonly used with management and workload clusters, the autoscaler implementation may actually have two kubeconfigs so that it can monitor the Cluster API resources in the management cluster and the nodes and pods of the workload cluster.
When deploying the Cluster Autoscaler we know the Kubernetes type information for the MachineSet and MachineDeployment types, and this is what the autoscaler needs in order to configure the clients and informer caches for those types. This helps to ensure that we have good performance when interacting with the Kubernetes API server. But, something that we might not know when starting the autoscaler is the type information for the Machine templates.
Machine template types will be specific to the provider implementation and can also be dynamically modified by a user during operation. Since the MachineSet and MachineDeployment types utilize an ObjectReference to point at their templates, this means that they could be anything the user desires. This presents a configuration issue in the autoscaler as we don’t necessarily know all these types beforehand, and thus won’t be able to start informer caches when we start the autoscaler.
If we want to implement scaling from zero, we need to have the information from the Machine templates so that the autoscaler can properly predict which node groups to expand.
Building Informers at Runtime
To get the best performance from Kubernetes we want to cache objects as they are returned from the API server. The controller-runtime project does much of this automatically, but as the autoscaler uses client-go this means we must engage those caching mechanisms ourselves.
Let’s look at how the management client is configured for the Cluster API
provider. Taken from the newMachineController function
which is called at startup by the autoscaler.
It starts by creating an Informer factory for the client. This allows us to create Informers for any of the objects we want.
managementInformerFactory := dynamicinformer.NewFilteredDynamicSharedInformerFactory(managementClient, 0, namespaceToWatch(autoDiscoverySpecs), nil)
If MachineDeployments are available, we create an Informer for them.
if machineDeploymentAvailable {
gvrMachineDeployment = schema.GroupVersionResource{
Group: CAPIGroup,
Version: CAPIVersion,
Resource: resourceNameMachineDeployment,
} }
machineDeploymentInformer = managementInformerFactory.ForResource(gvrMachineDeployment)
machineDeploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{})
}
Likewise, MachineSet and Machine Informers are created.
machineSetInformer := managementInformerFactory.ForResource(gvrMachineSet)
machineSetInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{})
machineInformer := managementInformerFactory.ForResource(gvrMachine)
machineInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{})
At this point our management client Informers have all been created and we are almost ready to use them. There is one final piece to ensure that these Informers will be automatically updating their caches.
The machineController.run method
contains the logic that will kick everything into motion.
Starting the Informer factories is key as this will set off the goroutines that will sync the caches.
c.workloadInformerFactory.Start(c.stopChannel)
c.managementInformerFactory.Start(c.stopChannel)
Lastly, we wait for the caches to sync the first time so that the autoscaler can function properly.
if !cache.WaitForCacheSync(c.stopChannel, syncFuncs...) {
return fmt.Errorf("syncing caches failed")
}
So far everything that has been done has been done at startup before the autoscaler has begun to process scaling operations. To understand the next part we should talk a little about how scaling from zero is implemented for Cluster API.
Scaling From Zero, the Cluster API Way
There are two primary methods to engage the Machine template information in a
Cluster API deployment. Either by adding annotations to your MachineSets and
Deployments, or by having the information supplied in the status.capacity
field of the infrastructure template resource.
The annotation method is very straightforward and requires no extra changes to the way that the autoscaler reads the MachineSet and MachineDeployment resources. It is also easy for users to engage as they have the power to add the annotations. An example can be seen in the README file for Cluster API in the Autoscaler.
The status.capacity field method requires that the Cluster API infrastructure
provider you are using (and keep in mind this is not the Cluster Autoscaler provider)
have implemented the necessary changes to add this information.
When the autoscaler calls the CanScaleFromZero function
, it will check first the annotations and then look for the infrastructure
template to see if the status.capacity field is there. The logic for getting
the template all boils down to the
getInfrastructureResource function. Let’s take a look at what it does.
func (c *machineController) getInfrastructureResource(resource schema.GroupVersionResource, name string, namespace string) (*unstructured.Unstructured, error) {
// get an informer for this type, this will create the informer if it does not exist
informer := c.managementInformerFactory.ForResource(resource)
// since this may be a new informer, we need to restart the informer factory
c.managementInformerFactory.Start(c.stopChannel)
// wait for the informer to sync
klog.V(4).Infof("waiting for cache sync on infrastructure resource")
if !cache.WaitForCacheSync(c.stopChannel, informer.Informer().HasSynced) {
return nil, fmt.Errorf("syncing cache on infrastructure resource failed")
}
// use the informer to get the object we want, this will use the informer cache if possible
obj, err := informer.Lister().ByNamespace(namespace).Get(name)
if err != nil {
klog.V(4).Infof("Unable to read infrastructure reference from informer, error: %v", err)
return nil, err
}
infra, ok := obj.(*unstructured.Unstructured)
if !ok {
err := fmt.Errorf("Unable to convert infrastructure reference for %s/%s", namespace, name)
klog.V(4).Infof("%v", err)
return nil, err
}
return infra, err
}
We can see that this function does some things that look very familiar to the
newMachineController function. The first thing to notice is the ForResource
call that is made on the Informer factory. This function will return an Informer
for the requested resource. If that Informer already exists on the controller,
then the factory will return the cached Informer, otherwise it will create a new
one. In this manner the call is safe to make multiple times for the same resource.
The next thing to notice is the Start call that is made on the Informer
factory. This step is necessary and something that caused great consternation
for several days as we tried to discover why our new Informers were not
updating. As it turns out, the Start method is safe to call multiple times
as it will check to see what is running and then start anything that hasn’t
already been started.
We then perform a WaitForCacheSync just as we did in the machineController.run
method. This will ensure that we get an update before we attempt to find the
infrastructure template. We could avoid doing the sync here, but that would mean
we would almost certainly fail the first time this function is called, which
would cause a cascade of failures which would prevent scaling in some cases. The
sync that happens here is quick and won’t block the operation of the autoscaler.
Lastly, we invoke the Lister().ByNamespace(namespace).Get(name) calls on the
informer. This will allow us to get the resource from the Informer cache, it
will not make a new call to the API server. At this point we should have the
data, or an error, and we massage it a little bit before returning to the
outside function.
This keystone was the last piece in our efforts to bring the scaling from zero feature to Cluster API. Before adding this function we were hammering the API server with calls to update the infrastructure template resources. This would end up in calls getting throttled as the client-go internals are smart enough to know when you are making too many calls to the API server in a short period of time.
Three Years in the Making
This is probably one of the longest efforts I have worked on in an open source community. It started even before our discussion in the Cluster API community as a feature in OpenShift (which uses a subset of primitives from Cluster API) that another group of engineers developed. It was handed to me as part of a team transition process as I joined the cloud infrastructure team.
When I took over the feature, we only had a ticket about bringing the feature to the upstream community. The discussions that had taken place about scaling from zero in Cluster API were nascent. But over the months we talked about the issue, had several deep dive sessions, and ultimately ended up with a design that the community agreed upon. It was then in my court to implement the changes for Cluster API and get it all merged.
Today we can say that the original journey has ended. The main feature is now available for Cluster API users. I’m sure there will be bugs, there always are, and potentially calls for new features in this code. I will be happy to see it all. It’s been a tremendous adventure so far and I am curious to see where it goes next.
Special thanks to all the community members who helped bring this feature to life. It truly does take a village to raise an open source project and I feel that we came together as one to make this something we can all enjoy.
Stay safe out there, and as always, happy hacking =)