I started learning the Python language back in the late 2000s while I was working at a company writing global positioning software for in-car navigation. It was a fun job and a great team to work with, and I had rejoined them after a year hiatus to lead an effort of converting the software stack from Windows CE to Linux. We were also building a new hardware platform, but I was always on the software side and left the physical bits to my capable colleagues. I was able to use the language to great effect when creating a D-Bus interface library that our application developers could use to communicate between host apps, and again when creating a cross-compiling harness to build entire ARM root filesystems (this was in the days when Yocto and Buildroot were young).
Over the years my love of Python continued and deepened as I learned to use it for writing all sorts of applications, eventually working on the OpenStack project (which was pretty much all server side Python). I’d venture that next to nearly two decades of C experience, Python is the second best language that I know. Which brings me to today’s example.
Making a molehill out of a mountain

One of the areas of Kubernetes that the team I’m on at Red Hat maintains for OpenShift are the Cloud Controller Managers. These are a set of Kubernetes controllers that run in-cluster to help make integrating with the underlying infrastructure smoother. As you might imagine each one of these controllers is written specifically for a single infrastructure provider. In the past this code had all been integrated into the main Kubernetes code repository, but as maintaining these bits in a common place does not scale well with the addition of ever more providers, there has been an effort to remove them from the main source repository.
As part of my work at Red Hat, and with the Kubernetes community, I have been investigating ways that we can grow the testing coverage for these new external cloud controller managers. One of the things I would like to do, if possible, is create a way for each provider to write their own interface implementation which would allow utilizing a central set of tests for all providers, current and future. To that end I have been browsing the upstream end-to-end tests which exist in the Kubernetes repository.
One of the core pieces of functionality for cloud controller managers is watching Kubernetes Services and ensuring that they are backed by a load balancer (where applicable). These tests are scattered throughout the Kubernetes end-to-end tests and I wanted to find a convenient way to find them all. A quick suggestion from Andrew , one of the SIG Cloud Provider chairs, was to use the Ginkgo binary tool with regular expression to find the tests. Which turned out to be a great suggestion because with a quick command line I was able to parse all the descriptions into a formatted JSON file. The command looked like this:
$ ginkgo -r --dry-run -v --focus .*[sS]ervice.* --json-report ./service-tests.json --keep-going kubernetes/test/e2e/...
I ran this command from the parent directory of the Kubernetes repository on
my local host. What it does is to do a “dry run” of all the tests, recursing
through directories, focusing only on tests with the regular expression
.*[sS]ervice.* in their hierarchy text (the stuff in the It("does stuff") clauses and whatnot),
and then writes the output to a file named service-tests.json. All while
continuing past any failures.
After running this command, I end up with a huge JSON file:
-rw-r--r--. 1 mike mike 9.1M Dec 8 14:57 service-tests.json
and looking inside it doesn’t get much better:
{
"ContainerHierarchyTexts": null,
"ContainerHierarchyLocations": null,
"ContainerHierarchyLabels": null,
"LeafNodeType": "SynchronizedBeforeSuite",
"LeafNodeLocation": {
"FileName": "/home/mike/dev/kubernetes/test/e2e/e2e.go",
"LineNumber": 77
},
"LeafNodeLabels": null,
"LeafNodeText": "",
"State": "passed",
"StartTime": "0001-01-01T00:00:00Z",
"EndTime": "0001-01-01T00:00:00Z",
"RunTime": 0,
"ParallelProcess": 1,
"NumAttempts": 0,
"MaxFlakeAttempts": 0,
"MaxMustPassRepeatedly": 0
},
it’s 278000 some odd lines of those entries. This is gonna take a while…
The serpent lurking in the jungle
As I was staring at these entries, starting to get a little cross-eyed, I wondered if I might use a script or something to pull all the files and line numbers out, maybe associated with their titles. Just something to pair down the raw the data in the file. Then inspiration struck me, I could write a small Python application which could create an HTML page with links to all the test files. I could then use my browser to at least parse things in a more convenient manner.
The architecture I was imagining looked something like this:
tests.json
| +-----------------------------+
v +-> | http://localhost/index.html |
+--------------------+ | +-----------------------------+
| Python http.server | --+
+--------------------+ | +--------------------------------------+
^ +-> | kubernetes.git/test/e2e/framework.go |
| +--------------------------------------+
kubernetes.git/
where the Python HTTP serving is running from my local Kubernetes directory, taking a Ginkgo output JSON file as input, and serving up an index page and source files. I knew Python had all the necessary building blocks in the standard library; JSON processors, HTTP servers, plenty of string formatting options.
I didn’t want to get too complicated as I realized two things; I didn’t want to spend more than a couple hours putting it together, and I didn’t want extra dependencies, only the Python standard libraries. My reasoning for the first was that any extra time spent hacking on this tool added to the total time for the investigation and I was very sensitive about not getting lost in a tool sharpening exercise. The second reason was that I didn’t want to contend with any sort of virtual environments or other packaging tools. I knew that all the building blocks I needed were in the standard library, if I was shrewd I could do this without installing extra helpers (no matter how nice they are!).
What I ended up with is something I call biloba.py , named after the humble tree, which at 170-ish lines of Python is one of the more compact but useful applications I’ve written, and I’m also quite proud of myself for accomplishing all the goals. It uses only the standard library, and serves a web page built from the entries in the source JSON. The main index has links which open into separate tabs that take you directly to the source for the test. It’s fairly minimal, but allowed me to take that list of tests and look through all of them within the span of about a week. The output looks like this:
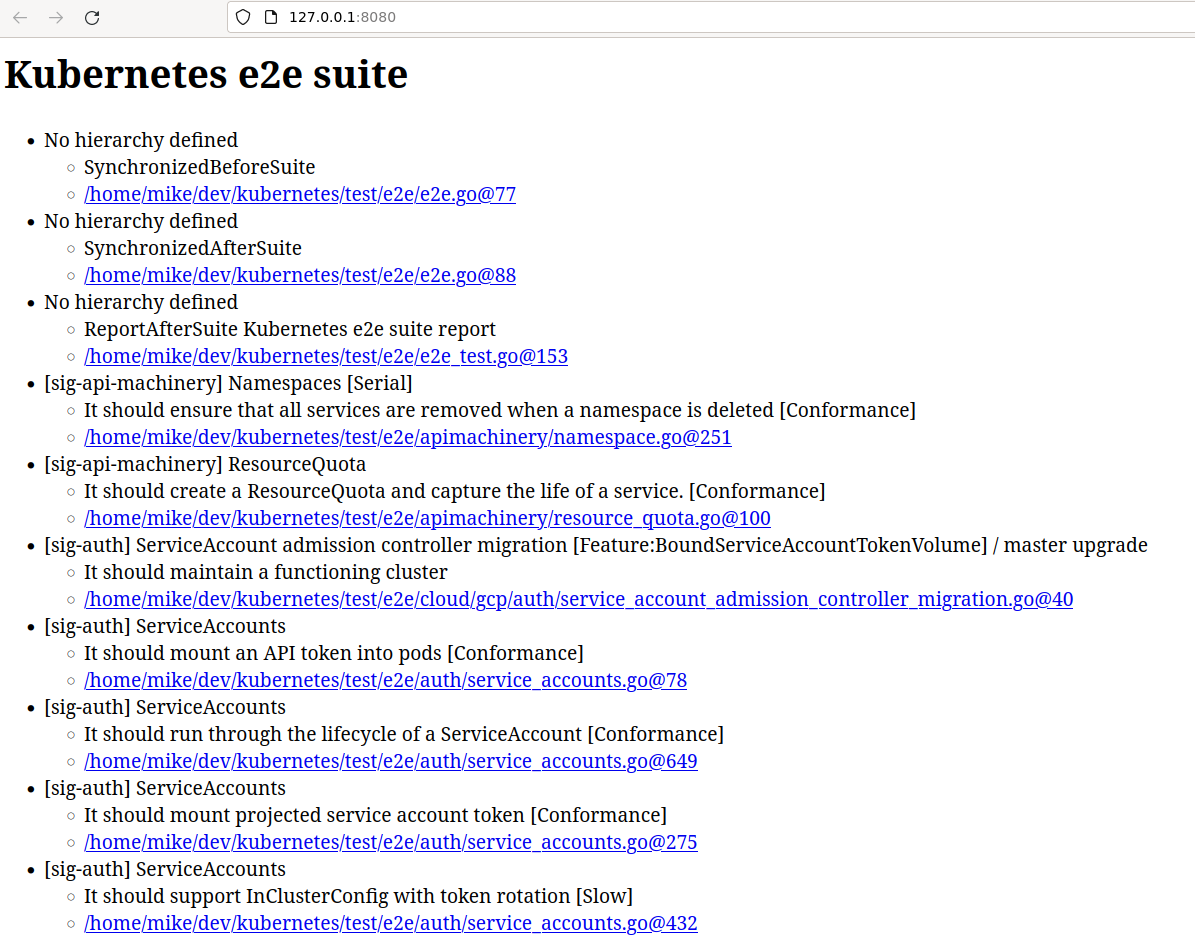
and the links to the code open into new tabs that are fairly plain:
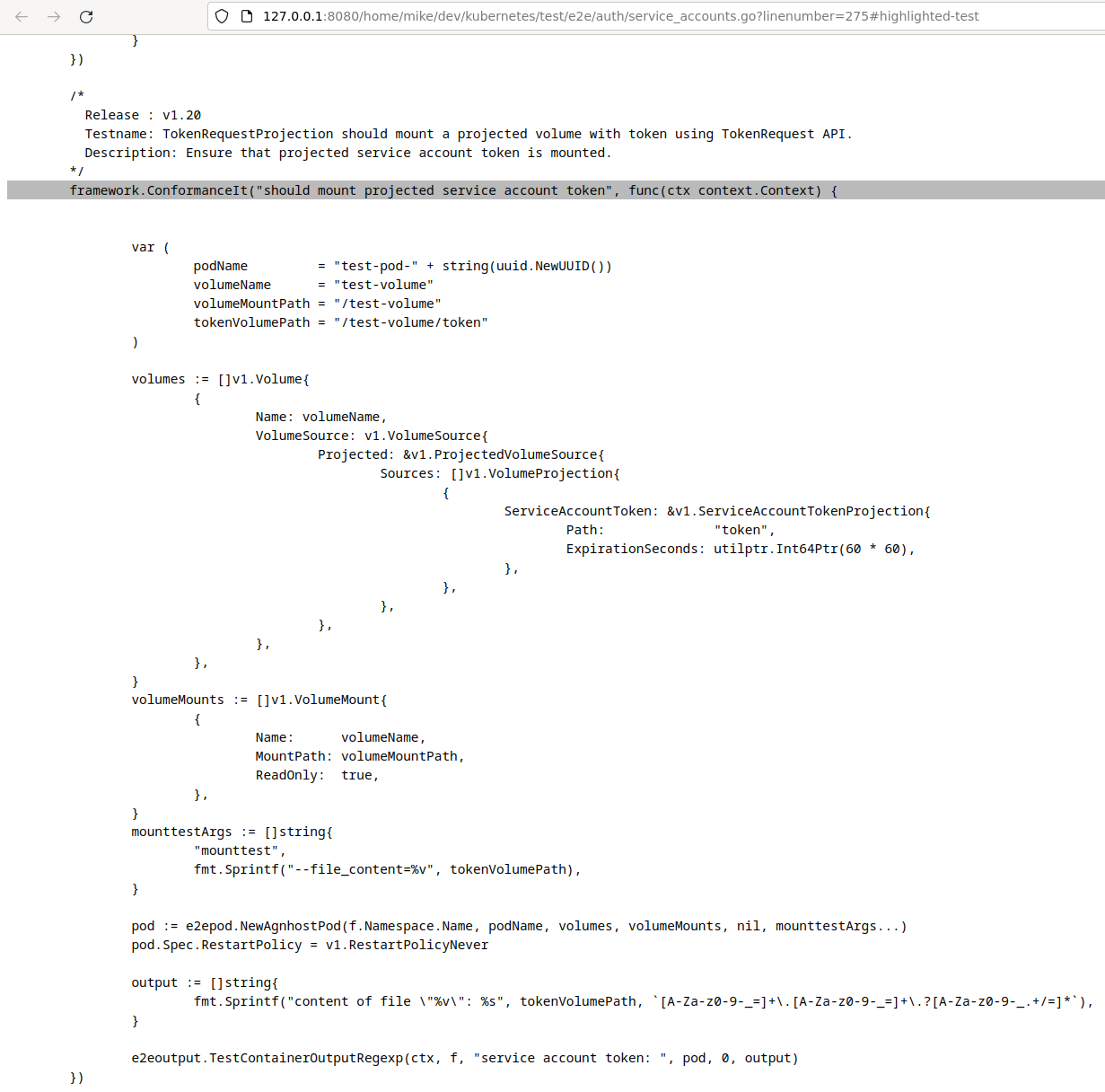
Simple, but effective.
What does it do?
Since it’s so small, let’s take a look at some of the choices I made and perhaps I can give some of my reasoning. Before we get started though, I’d like to acknowledge at the outset that Python is a dynamically typed language (although it does have options for static typing), and as such I tend to use it as a way to sketch out applications quickly. I like it’s pseudo-code style and the dynamic typing allows me to run quickly with scissors, this might not be to every person’s liking and I acknowledge that bias at the outset.
HTML
html_template = '''
<html>
<head>
<title>Biloba</title>
<style>
span.highlight {
background: #bababa;
display: block;
}
</style>
</head>
<body>
{body}
</body>
</html>
'''
index = html_template.format(body='Not generated')
The first part here establishes a template that I will use to create the wrapper page that holds all the other pages. I can reuse this for the index and for the code pages. It is also marked up for Python’s format string syntax, which makes it convenient for that reuse. I also declare a global variable for the index page so that I can have a value to know if things did not load properly, and to reuse with the handler and main functions.
Data Helpers
class Suite:
def __init__(self, suite):
self.reports = []
self.description = suite.get('SuiteDescription')
if self.description is None or len(self.description) == 0:
self.description = 'No suite description set'
self.path = suite.get('SuitePath')
if self.path is None or len(self.path) == 0:
self.path = 'No suite path set'
for i, report in enumerate(suite.get('SpecReports', [])):
if report.get('State') != 'passed':
continue
try:
newreport = Report(report)
logging.info(f'processed report for {newreport.filename}@{newreport.linenumber}')
self.append_report(newreport)
except Exception as ex:
nl = report.get('LeafNodeLocation', {})
fn = nl.get('FileName')
ln = nl.get('LineNumber')
logging.error(f'error processing report for {fn}@{ln}')
def append_report(self, report):
self.reports.append(report)
self.reports = sorted(self.reports, key=lambda r: r.hierarchy)
class Report:
def __init__(self, report):
hierarchy = report.get('ContainerHierarchyTexts')
if hierarchy is None or len(hierarchy) == 0:
hierarchy = ['No hierarchy defined']
hierarchy = ' / '.join(hierarchy)
if len(hierarchy) == 0:
hierarchy = 'No hierarchy text set'
self.hierarchy = hierarchy
logging.debug(self.hierarchy)
self.text = report.get('LeafNodeText')
if self.text is None:
self.text = 'No leaf node text set'
leafnodeloc = report.get('LeafNodeLocation', {})
self.filename = leafnodeloc.get('FileName')
self.linenumber = leafnodeloc.get('LineNumber')
self.nodetype = report.get('LeafNodeType', '')
These next two classes, Suite and Report, are convenience wrappers that
allow me to transform from the JSON format to an API that I can use when
generating HTML pages. Where possible I try to have it fail gracefully with
default messages that are easy to spot in the generated HTML content. I also
combine the hierarchy text into a more readable format and save the paths to
the individual source files with line numbers.
HTTP
class BilobaHttpRequestHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
logging.info(self.path)
if self.path == '/':
content = index
body = content.encode('UTF-8', 'replace')
self.send_response(HTTPStatus.OK)
self.send_header('Content-Type', 'text/html')
self.send_header('Content-Length', str(len(body)))
self.end_headers()
self.wfile.write(body)
elif 'favicon' in self.path:
super().do_GET()
else:
# if not the index, then try to load the file and inject in an html wrapper
try:
path, param = self.path.split('?', maxsplit=1)
linenumber = int(param.split('=', maxsplit=1)[1])
logging.debug(f'attempting to load {path}, highlighting linenumber {linenumber}')
content = '<pre>\n'
with open(path) as fp:
lines = fp.read().splitlines()
for i, line in enumerate(lines):
if i+1 == linenumber:
content += f'<span id="highlighted-test" class="highlight">{line}</span>'
else:
content += line
content += '\n'
content += '</pre>'
content = html_template.format(body=content)
body = content.encode('UTF-8', 'replace')
self.send_response(HTTPStatus.OK)
self.send_header('Content-Type', 'text/html')
self.send_header('Content-Length', str(len(body)))
self.end_headers()
self.wfile.write(body)
except Exception as ex:
logging.debug(ex)
super().do_GET()
This next part is where things get a little tricky. This class builds upon Python’s
standard library implementation for the http.server.SimpleHTTPRequestHandler to
create a richer interface. By default, the SimpleHTTPRequestHandler will create
the directory browser view that is familiar to anyone who has tried running
python -m http.server in their terminal (go try now if you haven’t XD). But, in
biloba.py I’d like to override that action when I see a request for /
or any other URL that looks like a directory. I’m overriding the do_GET function
of the base class so that I can inspect every HTTP GET request that is received.
The if / elif / else clause is where we choose to either send back the index page
if the request is for the root, or ignore if a request for a favicon, and lastly
try to open the URL as a file. There is also some logic to pull out the line
number parameter, if it exists, and then add the highlighted line to the code
file rendered template. If all else fails, or there is an exception, this function
hands control over to the parent’s implementation because it has much better support
for errors and erroneous input.
Main
def main(filename):
fp = open(filename)
report = json.load(fp)
suites = []
for i, suite in enumerate(report):
try:
newsuite = Suite(suite)
logging.info(f'created suite for {newsuite.path}')
suites.append(newsuite)
except Exception:
logging.error(f'error processing suite at index {i}')
continue
body = ''
suites = sorted(suites, key=lambda s: s.description)
for suite in suites:
if len(suite.reports) == 0:
continue
body += f'<h1>{suite.description}</h1>\n'
body += '<ul>'
for report in suite.reports:
body += f'<li>{report.hierarchy}<ul>'
if len(report.nodetype) > 0 :
body += f'<li>{report.nodetype} {report.text}</li>'
else:
body += f'<li>{report.text}</li>'
body += f'<li><a href="{report.filename}?linenumber={report.linenumber}#highlighted-test" target="_blank">{report.filename}@{report.linenumber}</a></li></ul></li>'
body += '</ul>'
global index
index = html_template.format(body=body)
server_address = ('127.0.0.1', 8080)
httpd = http.server.HTTPServer(server_address, BilobaHttpRequestHandler)
try:
print('serving at http://127.0.0.1:8080/')
httpd.serve_forever()
except KeyboardInterrupt:
logging.warning('\nKeyboard interrupt received, exiting...')
sys.exit(0)
I like to build my Python applications with a main function, mainly to help
me remember where the whole thing starts. In this case, the main does a couple
things. First it tries to process the file name it is given as a JSON file and
create code versions of the suites and reports that exist within it, also sorting
these by name.
Next, it creates the HTML for the index page, with its list of test names and links to the individual code files.
Lastly, it starts Python’s standard HTTP server using the custom handler class as the default handler. This server is not meant for production use cases, but running it locally in development is perfectly fine for my use case. I also wrap this command with an exception handler to make the eventual “control-c” quit a little more tidy.
Boilerplate
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Reformat info from a Ginkgo test report JSON file")
parser.add_argument('filename', help='the json file to process')
parser.add_argument('--debug', action='store_true', help='turn on debug logging')
args = parser.parse_args()
if args.debug:
logging.basicConfig(level=logging.DEBUG)
main(args.filename)
Finally comes the Python boilerplate we are all familiar with when writing application start code. I also tend to add my argument configuration stuff in these wrappers, and then pass in the arguments I need to the main function.
What’s next for the tiny biloba.py
I fixed one minor thing along the way, which turned out to be a 2 line change, but otherwise I’m actively resisting putting more time in on it. I’m not sure I will need it again, although if I do then I will probably add a little styling to the code pages in the form of line numbers and maybe a little background color.
Another thought I had was to add the ability for biloba.py to run the ginkgo command and harvest the output to a temporary file. I’m not quite sure if that would be useful, but I think if I start to do more of these “grep” style runs then I might add that.
I was super stoked with building this little application, it really turned what looked like several mountains of work into something that was very manageable. The power of modern tools like Python, and many other languages which I could have used, has really amazed me over the years. I encourage every out there to grow their tool box, whether with Python, another language, or even an entirely different piece of software all together. If you are looking for some place to learn Python, check out MIT’s Introduction to Computer Science and Programming in Python. It’s a free course with videos and assignment material, it does use an older version of Python but all the core principles are still useful. I hope you get out there and have some fun building your tool box out, and as always happy hacking =)