Recently I’ve had the need for a new type of application skeleton that I am wanting to use more and more frequently in my daily hackings. Namely, an application that can listen to an Apache Kafka topic and then display the data as it arrives on a web page without the need for the page to reload. So, we are talking about something that can use websockets to talk to the front end as well as subscribe to a Kafka topic.
If you are familiar with web development then you probably know there are many different ways that I can skin this cat, so to say. As I was exploring options I knew I wanted to use Patternfly to make the display nice and consistent. I also wanted to make use of the cool charts from C3.js, and lastly I wanted to use React as well to put myself on good footing for future expansion. I’m not sure all the ways I might need to mutate this application and it seems like Patternfly is throwing in with React as a front end target.
So far so good, it seems like I have a solid Javascript/HTML/CSS application going. There are bindings for Kafka in Javascript, and some simple steps to getting started with a React front end, it’s going to be a good saturday of coding. But, me being me, I had to make some unorthodox decisions along the way and thus my gumbo got a little spicy.
Starting at the front
I’ve been getting more and more comfortable with the reactive front end frameworks, and while in general I enjoy working with Vue.js this time I needed to use React. I have used React in the past, but I needed some refreshers especially since I was integrating with Patternfly and a websocket.
The React web page has a
great tutorial with local deployment instructions, and I cribbed heavily from this
to start my exploration. The react-create-app package was a great way to
start and I got my project off the ground before long. I wrote up a couple quick
components for the chart I wanted (sparkline) and a simple console display,
added some quick logo art, and within an hour or two i had a basic page with a chart
that had no data:
Pretty boring so far, but that’s ok I just needed to get a simple display up
with the chart in place and now I could start plumbing through the data. But
this got me thinking about what I had done so far. After running the initial
create scripts and hacking my code, I would run the yarn start command to make
this thing go. That in turn started some sort of development server which
was serving the page, and it automagically opened my browser to the local
display address. Was I going to need some sort of server? or backend
for the front page to talk to?
Luckily, the React tutorial has a nice section on deployments with a couple suggestions. This actually proved to be a sticking point as it took me several attempts to get it right for my platform. I needed to move the default host port and webpack files were being very temperamental if I didn’t deploy them immediately after building the optimized packages. I’m still not exactly sure what was causing this, but I eventually got it running.
Who serves the servers?
My target environment with this application has always been OpenShift Kubernetes, so to really make that work I need apps that can be bundled into containers easily and then orchestrated on the platform. As I understood the React front end construction I had done so far, what I had was a simple way to make a static page that could be deployed. Assuming I could keep the websocket server as an entirely different entity, and embed its address into the static page, then I could just serve the React page from a simple static server. This seems like a win from the orchestration angle as it becomes much easier to scale individual pieces, and from the development angle it makes each component a separate concern. I like this =)
As I started to consider what the websocket server would do, and how I was going to be serving the client page as a set of static files. I quickly arrived on this architecture as my design:
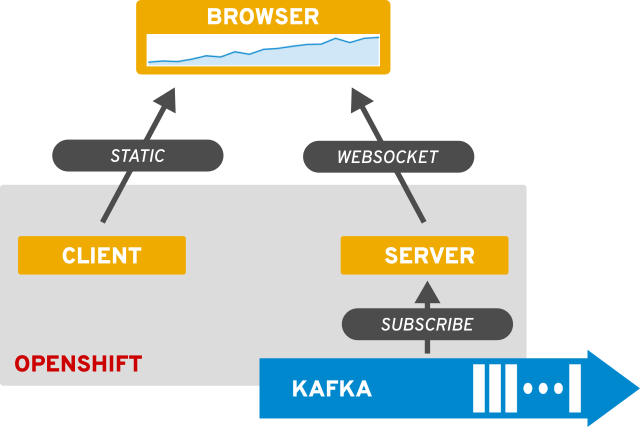
This seems really nice for what I want to do and will help to make my services as small and direct as possible. The last decision I needed to make was how to create the server. Perhaps because of my love for the language, or perhaps because I am a glutton for trying hard mode, I decided to write the server logic in Python. Yay, the gumbo gets thicker \o/
Now, you might be wondering why I didn’t write the server in Javascript with
Node.js, and that is a fair question. I’m not sure
exactly, some of it is style, other is my familiarity with the Python workflow
and the Kafka libraries. Ultimately, choosing Python allowed me to basically
copy the
kafka-openshift-python-listener
codebase and just slap on my websocket logic. It didn’t hurt that I had also
been eager to learn more about the Python asyncio package and this gave me a
perfect opportunity.
After several headaches navigating my way around threads and coroutines, I finally got the server working but not without making some sacrifices. Initially, I had the idea that I could engineer the server to only maintain a single Kafka consumer. This seemed ideal as it would limit the number of connection from the server to the Kafka brokers. I tried several techniques to isolate the Kafka listener and create a one way queue of updates from it to the coroutine serving the websockets. This became a real frustration and I couldn’t arrive at an adequate solution, so I made a sacrifice in that each websocket connection will have its own Kafka consumer.
I realize this may affect performance, but I figure if it does then the servers can always be scaled out to accomodate. Another learning experience in the land of containers, and one that got me thinking. I suppose this behavior might be perferrable in some cases as it is simpler to write, even if it might be more wasteful. The platform allows me to scale as needed if performance becomes an issue, I’m not sure what the extended effects on the Kafka side might be and I would love to develop some sort of test to determine the limits.
Shocking the beast to life
I had all the pieces working locally at this point, running in their various development environments on my laptop. I had a Kafka broker up thanks to the folks at Spotify for their image on Docker hub, and even wrote a small test emitter to create synthetic data. It was time to take the show on the road.
By using the Node.js
and Python source-to-image
builders, I was able to easily use the oc new-app command to quickly deploy
these applications on to OpenShift. And with the Strimzi Project
I had a simple way to deploy Kafka as well, before long the entire thing was
up in my project:
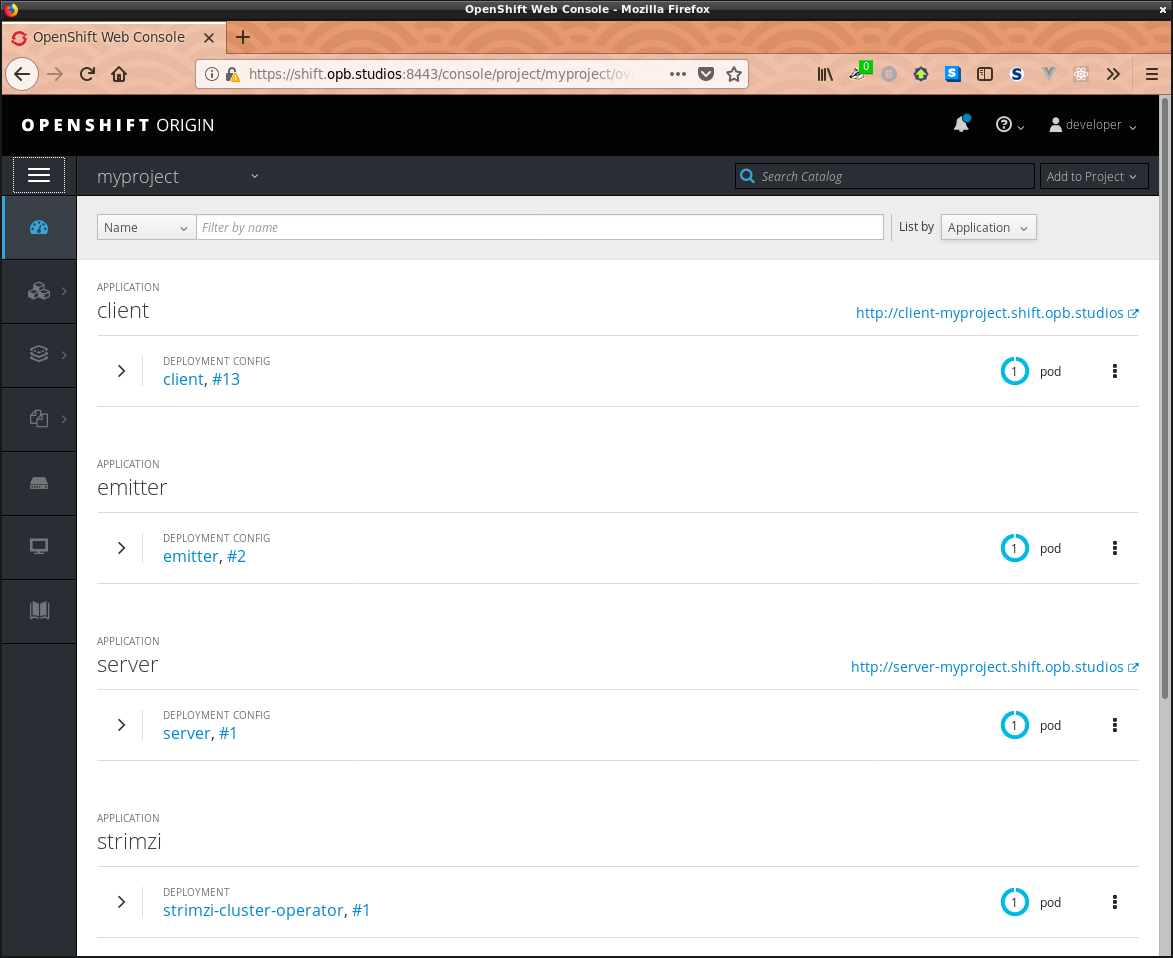
Even more amazing was that after a few small bumps and bruises wrangling the routes to my services, the front end was receiving websocket updates from the server with data flowing through. I wrestled to get things into the proper formats across the wire, but thankfully working with OpenShift made it really easy; I would just push commits to github and then instruct the platform to rebuild my stuff. I never needed to redeploy completely until I had broken things really badly. With live data streaming through I was now looking at this:
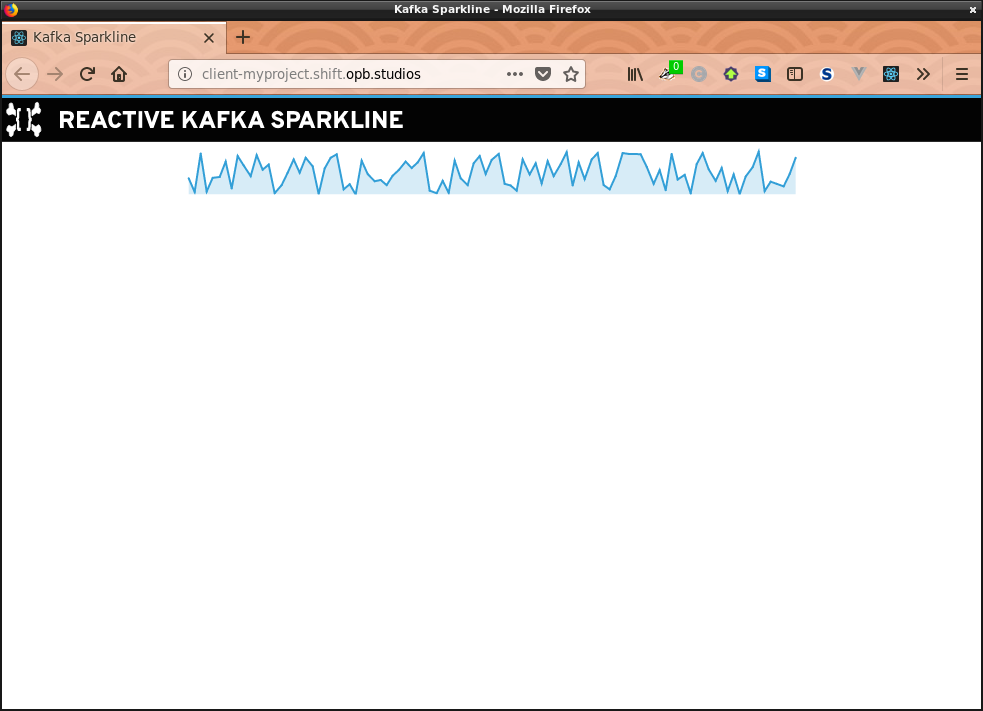
Lessons learned, next steps, yadda yadda
Wow, that was a ride. It was a long day of coding with at least 4-6 hours of reading and planning leading up to it. But, it was totally worth it! I have learned some new patterns and code that will help me accelerate other projects I’ve been hacking on. Hopefully it will help out others as well.
I would like to go back and add more comments to the code as well as some proper testing. Also I think the overall doc needs a bit of tidying, although all the instructions are there if you want to try it. The animation need some love as it’s not as smooth as I would like currently. And I would also like the page to be styled a little more. So, yeah, there are a laundry list of things I’d like to add on (oh yeah! change the Kafka message format to JSON).
I hope you enjoyed this story, if you have any questions please reach out, and if you would like to check out the code just look here:
and as always, have fun and happy hacking!