One of the aspects of working for Red Hat, and on the OpenShift product, that I get tremendous joy from are the activities that we have focused on empowering associates to spend time contributing to open source projects and our communities. Many companies have these types of agreements with their employees, Wikipedia refers to it as Side project time, most famously popularized by Google’s “20 percent time”. At Red Hat we call these times “Hack n’ Hustle” or “Shift week” depending on when they occur, but the primary goal is for us to have time working on passion projects, or contributing to upstreams, or even to be spending time in our physical communities giving back to those around us.
For awhile now, since at least April 2021 by GitHub’s record, I have been working on a project that I call “camgi.rs” (originally “okd-camgi”). Which originally stood for Cluster Autoscaler Must Gather Investigator (I guess it still does stand for that, we just don’t talk about it that way anymore). It was a tool that I started to develop to help with the arduous process of understanding why the cluster autoscaler had failed in a given scenario on OpenShift.
Now, to set the stage a little more, there is a debugging tool that we use heavily in OpenShift to help diagnose failures. That tool is called “must-gather”, and it produces a tarball full of all sorts of Kubernetes goodness; including log files, manifests, and even audit logs from a subset of the cluster in question. Must gather is very flexible and can be extended in many ways to add all sorts of custom information, but I will save that for another post. The main point here is that I wanted a visual way to quickly diagnose what was happening without having to open a dozen YAML and log files. So, camgi was born.
Looking at a must gather archive
At a very high level, the must gather archive contains a bunch of directories that all have various bits of information about the cluster and it looks something like this:
$ ls -l
total 6676
drwxr-xr-x. 1 mike mike 874 May 30 16:30 cluster-scoped-resources
drwxr-xr-x. 1 mike mike 142 May 30 16:30 etcd_info
-rw-r--r--. 1 mike mike 6824435 May 30 16:30 event-filter.html
drwxr-xr-x. 1 mike mike 14 May 30 16:30 host_service_logs
drwxr-xr-x. 1 mike mike 14 May 30 16:30 ingress_controllers
drwxr-xr-x. 1 mike mike 34 May 30 16:30 insights-data
drwxr-xr-x. 1 mike mike 44 May 30 16:30 monitoring
drwxr-xr-x. 1 mike mike 3332 May 30 16:30 namespaces
drwxr-xr-x. 1 mike mike 188 May 30 16:30 network_logs
drwxr-xr-x. 1 mike mike 66 May 30 16:30 pod_network_connectivity_check
drwxr-xr-x. 1 mike mike 28 May 30 16:30 static-pods
-rw-r--r--. 1 mike mike 550 May 30 16:30 timestamp
-rw-r--r--. 1 mike mike 78 May 30 16:28 version
That’s just the top directory, I ran a tree command on the archive and it says:
2745 directories, 4381 files
whoa! That is way too much to reproduce in this post, but i guarantee it’s got a ton of good stuff in there.
To make things much simpler, I wanted a web page that I could use to browse around and get a “bird’s eye view” of what is happening. So, that’s what I did. Today the camgi output looks like this on the summary page:
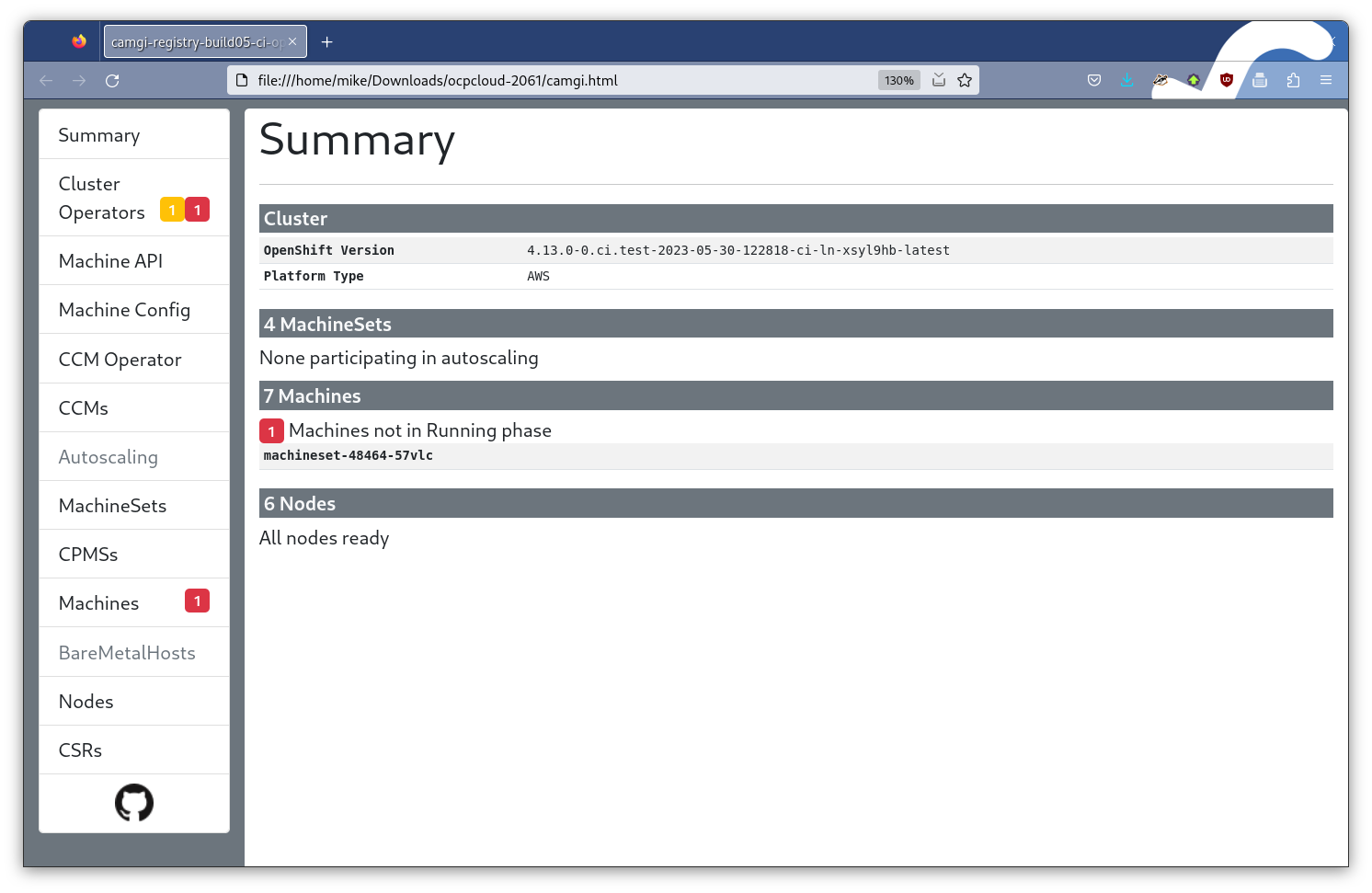
You can immediately see some information about the cluster state when the must gather was created. In this case (from a CI run) we can see that 1 Machine is not in a running state, and 2 ClusterOperators are having issues (one is not upgradeable, and another is degraded or not available). This tool started to change the way I could debug things and made it much quicker to find problems. It was also starting to have an affect on my colleagues as they started to ask for more features and custom resources to be added.
Diving a little deeper, we can see how this tool can be used to explore resource and log data.
Project history and design goals
When I first started planning this project I was inspired by the work of a colleague
who had started an HTML-based display (shoutout to Mike G!), and also by the inclusion of
a different HTML file in the must gather output. You might have noticed in the directory listing
above a file name event-filter.html. This file is a static HTML file with all the data included
within the page. You can use it to search and filter the events which were emitted from the cluster
during the capute period. I thought this was really cool, although I also acknowledge it’s
not the most frugal way to create an HTML page (more on this later).
So I went to my old favorite tool Python to begin hacking up a static page to contain all the data I wanted to highlight. This allowed me to rapidly prototype as I was able to use modules like Jinja, PyYaml, and the standard library to quickly manipulate the text data. But as I got requests to include the output into our build systems for continuous integration it became apparent that including all the necessary Python modules was going to be very difficult. It was at this point that I decided to re-write the project in Rust so that it could be built as a binary for distribution. I chose Rust because I wanted to learn more about the language and this seemed like a perfect opportunity.
After several months of development, I was able to release the new tool and get it included in our CI infrastructure as I could now have it downloaded during runtime. This process was difficult as I had to ensure that my builds would be usable within the containers that our CI uses to generate must gather artifacts. This was a trip down memory lane as I was fighting with glibc incompatibilities that really brought me back to my early C days. But finally, it was done and I was able to have it included in the output, which you can see today if you find the Prow output from a CI run on our many repositories.
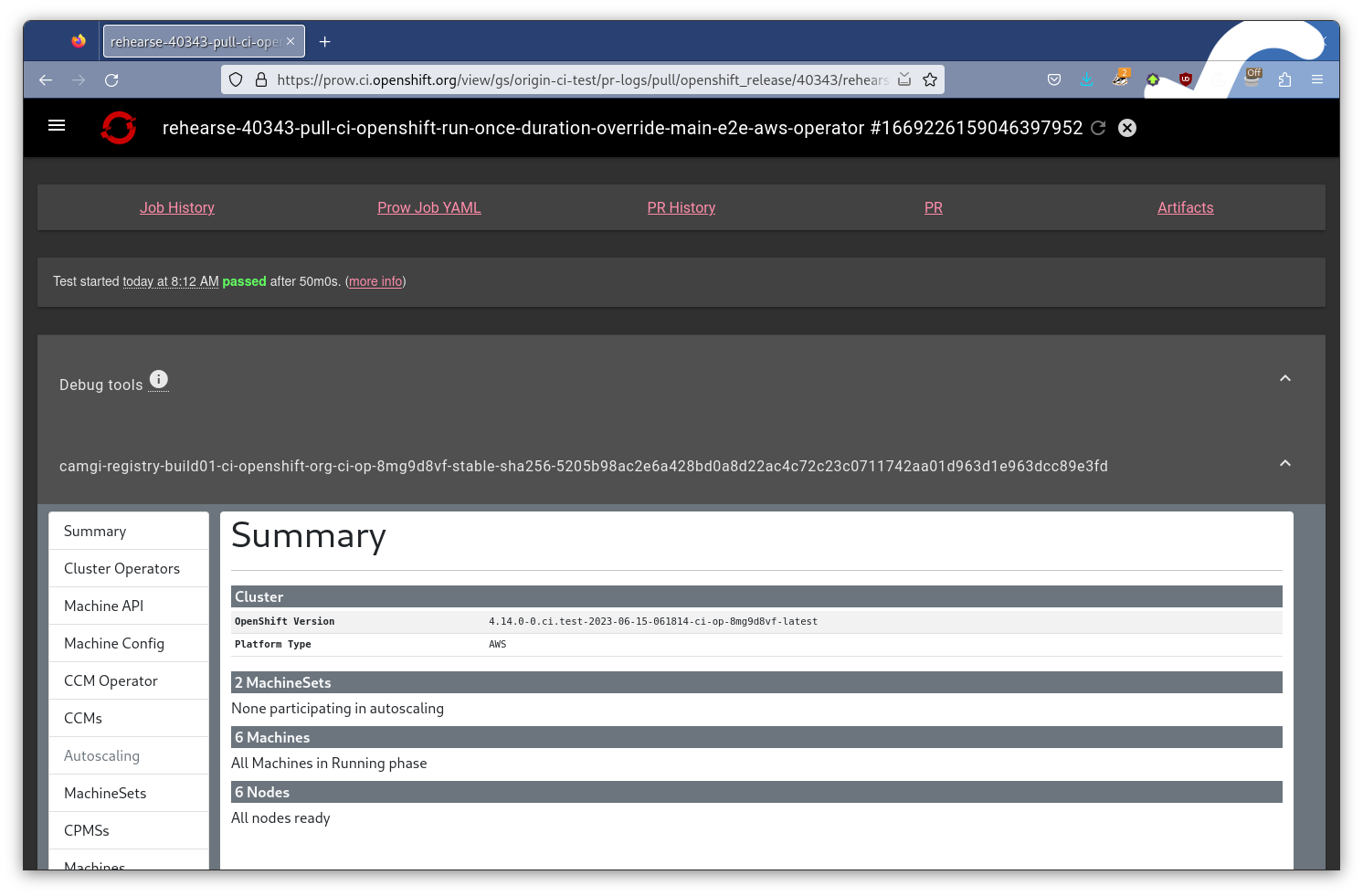
Having a single output file from the tool makes it very simple to include the artifact in whatever format we choose. Although it would be more efficient to have some sort of HTTP server hosting the files from the must gather, this adds a lot of overhead for how it is used and confines the way it can be included in other places. It does produce quite large files sometimes, especially when investigating clusters with many nodes that have been active for a long time. But usually the files are only being generated locally in those cases, so we aren’t passing around 500Mb HTML files, usually… XD
Operating camgi
Camgi itself is quite easy to install and operate. You can either get a binary release for Linux x86_64
targets from the releases page on GitHub, install it directly from source by cloning
the repo and running cargo build, or by installing from crates.io by running cargo install camgi.
Once installed simply run the camgi command with your must gather archive as a target, such as:
[mike@ultra] ~/Downloads/my-must-gather
$ camgi must-gather.local/ > camgi.html
Then open the resulting file in the browser of your choice.
Release 0.9.0 and the future…
We are currently winding down the latest Shift week at Red Hat, and as part of my activities I have added some new features and created the 0.9.0 release of camgi.
As part of my development process I have been opening issues and inviting my colleagues to help in the construction of camgi. Even though I don’t spend every week working on camgi, creating issues and reaching out to my peers for advice and guidance has been a tremendous help. When people ask for new features, find bugs, or identify areas of improvement I quickly open an issue to remember what has been asked. In this manner I help myself out for the future and maintain a nice queue of things to hack on, it’s been a tremendous experience for me.
I mentioned earlier that creating a giant static HTML file is not the most frugal way to handle this activity. One thing that I would really like to solve for the future is reducing the size of the log files that are included as I notice that sometimes the browser really has to crunch to make things work. This is one of my top goals for the future, but I still have some learning to do so that I can achieve it in a way that is convenient for people to access the full log files. We’ll see how it goes.
If you’ve made it this far, I hope this tale has at least been interesting and perhaps even inspired you to build your own projects or get involved with other collaborators. For me, I will be coding away on the way too many side projects I have and looking for ways to contribute back and become more involved with the open source community at large. And so, as always, stay safe out there and happy hacking =)